scrapy 分布式原理
scrapy 默认并不支持分布式,在过去,使用 scrapy 进行大规模爬取工作,一般需要提取做好网页地址的分割与分发,实现一种近似分布式。
现在,基于scrapy 的分布式框架越来越多,比较著名的有 scrapy-redis 以及 scrapy-cluster。在平时的工作之中,也是使用较为广的分布式框架。现在,我们以scrapy-redis 为例,进行 scrapy 分布式的介绍。
1. scrapy 单机架构
在了解 scrapy-redis 之前我们需要简单地回顾一下 scrapy 原生的架构。我们知道,scrapy 原生的任务调度基于文件系统,通过 JOBDIR 指定任务信息存储的路径。同时 scrapy 还会在本机维护一个爬取队列,用来调度爬取中的相关任务。
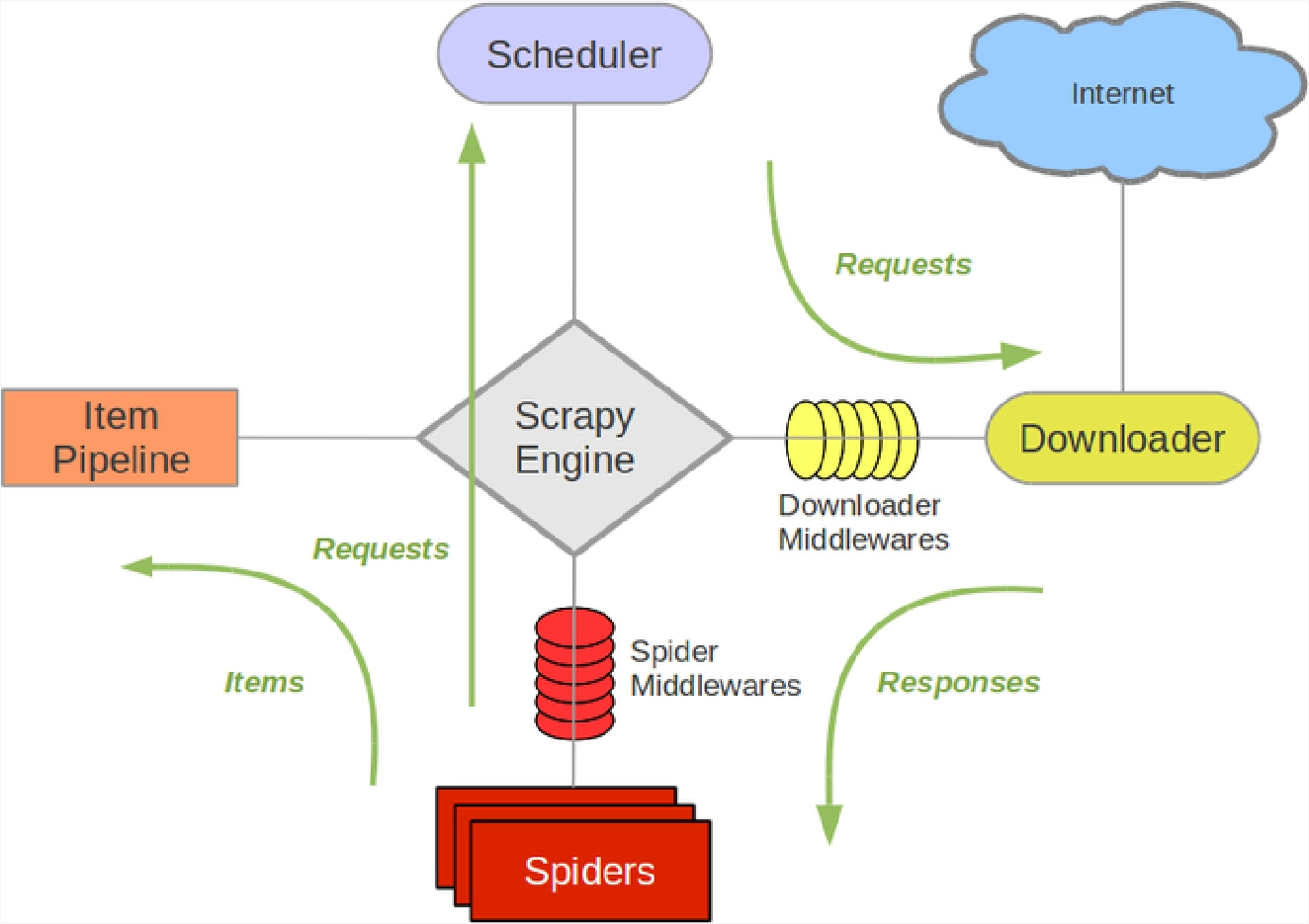
以上是 scrapy 的单主机架构图,其各个组件主要有以下几个功能:
(1) Scrapy Engine
引擎负责控制数据流在系统中各组件之间的流动,并在相应动作发生时触发事件。
(2) Scheduler
调度器负责从引擎接收 request,并将他们入队,以便之后引擎请求的时候,把 request 返还回去。
(3) Spiders
Spider 是 scrapy用户编写的用于分析 response 并提取 item,并获取额外跟进 url 的类。每个 spider 负责处理一个特定的网站。
(4) Item Pipeline
Item Pipeline 负责处理被 spider 提取出来的 item。典型的处理有清理、验证以及持久化
(5) Data flow
scrapy 之中的数据流由执行引擎控制,其过程如下:
- 引擎打开一个网站,找到该网站的 spider,并向该 spider 请求第一个要爬取的链接。
- 引擎从 spider 中获取第一个要爬取的 url 并在调度器以 request 方式调度。
- 引擎向调度器请求下一个要爬取的 url。
- 调度器返回下一个要爬取的 url 给引擎,引擎将 url 通过下载器中间件(请求 request 方向) 发送给引擎。
- 引擎从下载器之中接收到 Response 并通过 Spider 中间件(输入方向)发送给 Spider 处理。
- Spider 处理 Response 并返回爬取到的 Item 以及(跟进的)新的 request 给引擎。
- 引擎把(Spider 返回的)爬取到的 Item 给 Item Pipeline,并将(Spider 返回的)request 传递给调度器。
- 从上面的第二步重复,直到调度器之中没有更多的 request,引擎关闭该网站。
2. 基于 scrapy-redis 的分布式架构
scrapy-redis 是基于 redis 的scrapy组件,其基于 redis 的特性拓展了 scrapy 的相关组件:
(1) 调度器(Scheduler)
- 请求去重
通过 redis 的集合数据结构,在集合中存储每个 request 的指纹。在向 request 队列之中加入 request 前,首先验证该 request 的指纹是否已经加入集合中。 如果已经存在,则不添加请求到队列,否则把 request 加入队列并将指纹放入集合。
- 队列维护
引擎请求 request (spider发出的)时,调度器从 redis 的 request queue list 队列里依据优先级 pop 出一个request 返回给引擎,引擎将此 request 发给 spider 处理。
- 防止中断(断点续爬)
在每台 slave 主机的 scrapy 启动时候,master 主机会首先判断当前的 redis request 队列是否为空。如果不为空,则从队列中获取下一个 request 执行爬取;若为空,则重新开始爬取,第一台 slave 主机会执行爬取向队列之中添加 request
(2) Item Pipeline
- 分布式数据处理
引擎将(spider 返回的)爬取到的 Item 传给 Item Pipeline, scrapy-redis 的 Item Pipeline 会将爬取到的 Item 存入 redis 的 items queue list。可以依据 key 从 items queue 提取 item,从而实现 items processes 集群。
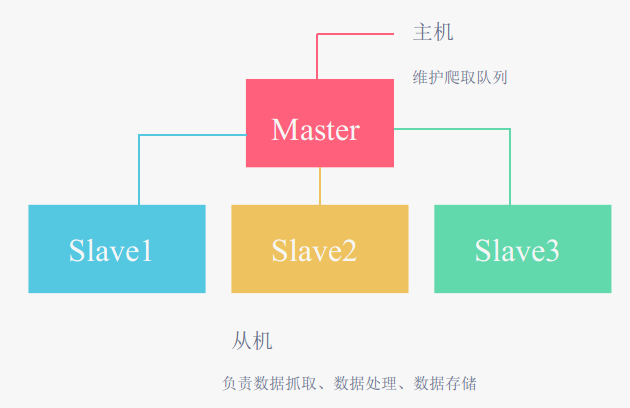
scrapy-redis 巧妙的利用 redis 的 list 实现 request 的 job queue 和 items queue,利用 redis 的 set 实现 request 的去重,把 scrapy 从单台主机(容器)拓展到了多台主机(多个容器)。
3. 基于 scrapy-redis 的两种策略
(1) 策略一
Slave 主机从 Master 主机获取任务,然后进行数据抓取,在抓取数据的同时生成新任务,并把任务返回给 Master。Matser 端只有一个 Redis 数据库,负责对 Slaver 提交的任务进行去重,加入待爬取队列。
在 settings.py 进行如下配置
# Enables scheduling storing requests queue in redis.
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# Ensure all spiders share same duplicates filter through redis.
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# Store scraped item in redis for post-processing.
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 300
}
# Specify the full Redis URL for connecting (optional).
# If set, this takes precedence over the REDIS_HOST and REDIS_PORT settings.
#REDIS_URL = 'redis://user:pass@hostname:9001'
我们需要启用 scrapy-redis 的 Scheduler 以及 Dupefilter,并添加数据库访问地址,当然我们也可以启用组件提供的 Item Pipeline。
我们可以看到,作为 scrapy-redis 的默认策略,scrapy-redis 调度的任务是 Request 对象,里面信息量比较大(url,callback 函数、headers 等信息),这样会造成爬虫速度的降低、还会占用较多的 redis 存储空间。
(2) 策略二
把 url 的生成与抓取任务分开,减少 Master 和 Slaver 主机之间的交流,通过生产者消费者模式,Master 端可以方便地重写去重策略(当数据量大时,进行去重优化,提升爬取速度还是十分重要的)
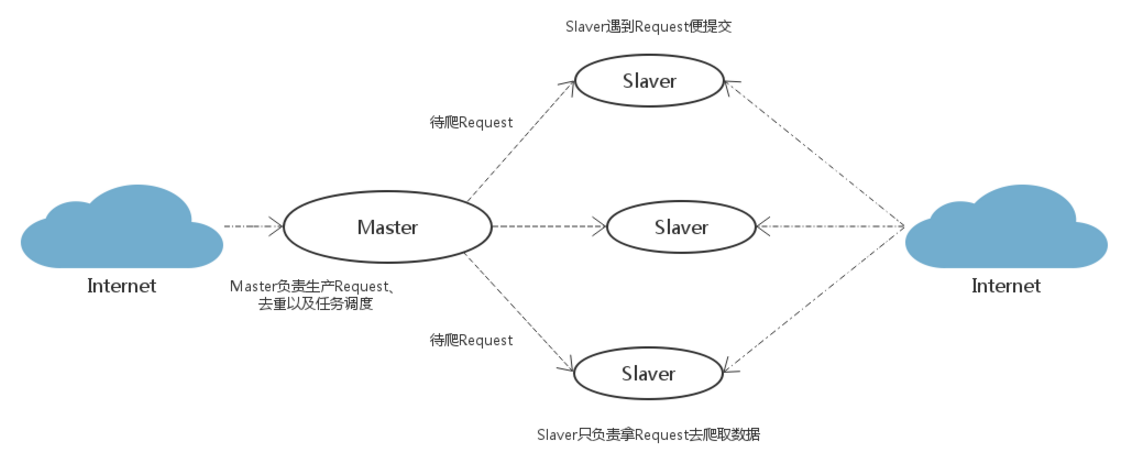
Feeding a Spider from Redis
在项目的 settings.py 文件中,配置好 redis 数据库的相关信息。
改写 spiders/ 目录下的 myspider.py
from scrapy_redis.spiders import RedisSpider
class MySpider(RedisSpider):
name = 'myspider'
def parse(self, response):
# do stuff
pass
- 运行爬虫
scrapy runspider myspider.py 或 scrapy crawl myspider
- 把链接推送到 reids 之中
redis-cli lpush myspider:start_urls https://google.com
当然我们也可以自己编写脚本进行 url 的管理调度。