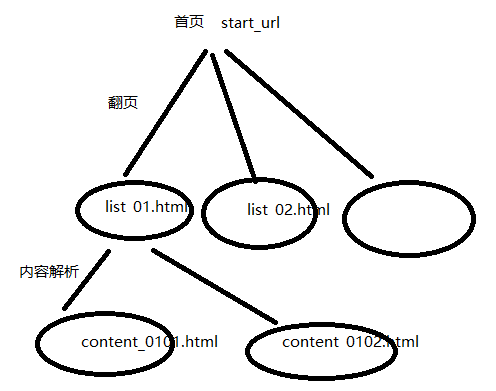
4.2 爬虫搜索策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的顺序排列也是一个很重要的问题,因为这涉及到先抓取那个页面,后抓取哪个页面。而决定这些URL排列顺序的方法,叫做抓取策略。深度优先和广度优先算法在爬取一个整站上经常用到,这里讲解一下这两个算法的原理以及使用过程。
1. 网站目录树
(1) 一个网站的url结构图
以知乎为例,知乎目前有发现、话题、Live、书店、圆桌、专栏主要的6个tab页。每个网站的url都是有一定的层次,如下图:发现explore、话题topic、Live lives、书店pub、圆桌roundtable、专栏zhuanlan都是在主域名zhihu的下一级,网站的所有内容都一层一层的类似一个树形结构。

(2) 网站url链接的结构图
当然,如果我们要做爬取整个网站的url时,我们必须要知道每个网站的url链接一般情况下都是存在环路的,也就是在下一级页面存在上一级页面的url链接,这样形成一个环路。当遇到这个情况时我们需要做url去重,一般的处理方式是把已经爬过的url放到一个list,每次爬取url的时候都去这个list查看下是否已经爬过,爬过的就跳过。

2. 深度优先搜索策略(Depth-First Search)
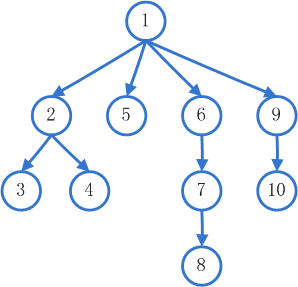
我们把网站的 Tab 理解成为一颗树的节点,当我们使用深度优先遍历算法。网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续跟踪链接。
3. 广度优先搜索策略(Breadth First Search)
宽度优先遍历策略的基本思路是,将新下载网页中发现的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。
有很多研究将广度优先搜索策略应用于聚焦爬虫中。其基本思想是认为与初始URL在一定链接距离内的网页具有主题相关性的概率很大。

4. 广度优先搜索和深度优先搜索
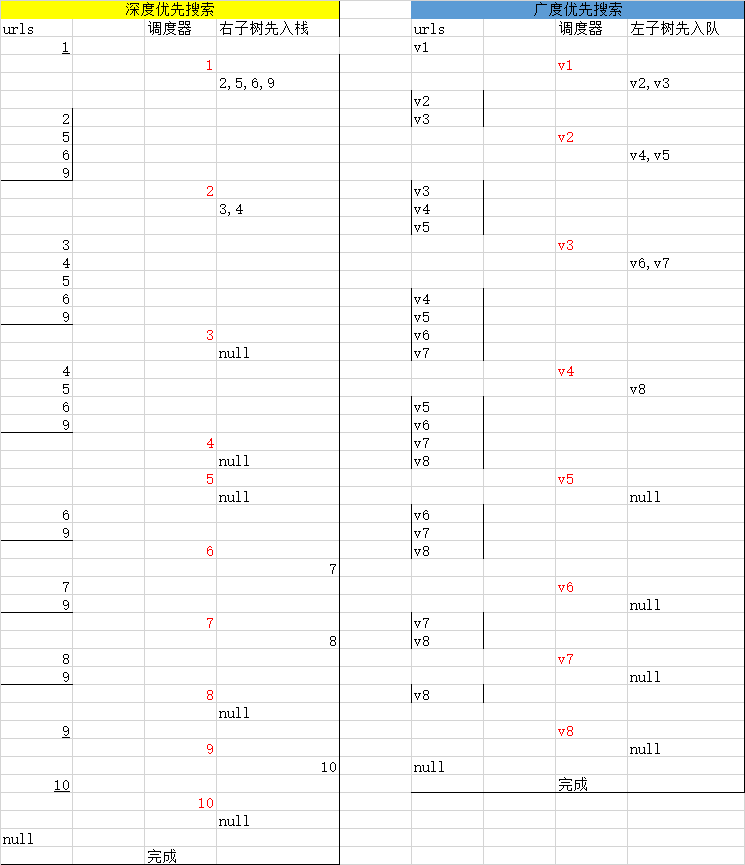
深度优先搜索算法涉及的是堆栈
广度优先搜索涉及的是队列。
堆栈(stacks)具有后进先出(last in first out,LIFO)的特征
队列(queue)是一种具有先进先出(first in first out,LIFO)特征的线性数据结构。
5. 搜索策略的选择
- 重要网页与种子站点的距离。
- 当多爬虫需要并行合作爬取时,可以采用宽度优先的方法
- 使用深度限制与宽度优先相结合的策略。
6. 引申:Scrapy爬取策略
默认情况下,Scrapy使用 LIFO 队列来存储等待的请求。简单的说,就是 深度优先顺序 。深度优先对大多数情况下是更方便的。如果您想以 广度优先顺序 进行爬取,你可以设置以下的设定:
DEPTH_PRIORITY = 1
SCHEDULER_DISK_QUEUE = 'scrapy.squeue.PickleFifoDiskQueue'
SCHEDULER_MEMORY_QUEUE = 'scrapy.squeue.FifoMemoryQueue'