4.4 基于 URL 的网页去重
我们知道数据采集之中有一块,很重要的工作就是数据的去重,一般而言分为2种,即基于 url 的去重,以及基于网页内容的去重,今天我们简单说明一下 url 去重原理。
1. 抓取历史的记录方法
假设要你写一个网络蜘蛛。由于网络间的链接错综复杂,蜘蛛在网络间爬行很可能会形成“环”。为了避免形成“环”,就需要知道爬虫已经访问过那些URL。给一个URL,怎样知道蜘蛛是否已经访问过呢?稍微想想,就会有如下几种方案:
将访问过的URL保存到数据库,利用索引去重。
用HashSet将访问过的URL保存起来。那只需接近O(1)的代价就可以查到一个URL是否被访问过了。
URL经过MD5或SHA-1等单向哈希后再保存到 HashSet 或数据库。
Bit-Map方法。建立一个BitSet,将每个URL经过一个哈希函数映射到某一位。
方法1~3都是将访问过的URL完整保存,方法4则只标记URL的一个映射位。以上方法在数据量较小的情况下都能完美解决问题,但是当数据量变得非常庞大时问题就来了。
方法1的缺点:数据量变得非常庞大后关系型数据库查询的效率会变得很低。而且每来一个URL就启动一次数据库查询是不是太小题大做了?
方法2的缺点:太消耗内存。随着URL的增多,占用的内存会越来越多。就算只有1亿个URL,每个URL只算50个字符,就需要5GB内存。
方法3:由于字符串经过MD5处理后的信息摘要长度只有128Bit,SHA-1处理后也只有160Bit,因此方法3比方法2节省了好几倍的内存。对了,不知道MD5 是啥的请点击: MD5.
方法4:消耗内存是相对较少,但缺点是单一哈希函数发生冲突的概率太高。
2. 基于 Bit-Map 方法的优化
上面的算法都忽略了一个重要的隐含条件:允许小概率的出错,不一定要100%准确!也就是说少量url实际上没有没爬虫访问,而将它们错判为已访问的代价是很小的——大不了少抓几个网页呗。所以方法4以及是比较接近我们的目标了。
在进一步深入前,我们先简单地介绍一下 Bit-Map 记录方法:
Bitmap可以理解为通过一个bit数组来存储特定数据的一种数据结构;由于bit是数据的最小单位,所以这种数据结构往往是非常节省存储空间,可以被一次性加载到内存中。
比如一个公司有8个员工,现在需要记录公司的考勤记录,传统的方案是记录下每天正常考勤的员工的 ID 列表,比如 2017-10-12:[1,2,3,4,5,6,7,8]。假如员工ID采用byte数据类型,则保存每天的考勤记录需要N个byte,其中N是当天考勤的总人数。另一种方案则是构造一个8bit(01110011)的数组,将这8个员工跟员工号分别映射到这8个位置,如果当天正常考勤了,则将对应的这个位置置为1,否则置为0;这样可以每天采用恒定的1个byte即可保存当天的考勤记录。
在大规模爬虫工作中,我们可以将URL的MD5值再次哈希,用一个或多个 BIT 位来记录一个URL,在MD5的基础上,可以从128位最多压缩到1位,一般情况,如果用4bit或者8bit表示一个url,也能压缩32或者16倍。
所以,在我们使用多个哈希函数以后,便可以有效降低 Bit-Map 记录方法里,冲突发生的概率。
3. Bloom-Filter 去重
Bit-Map 引入多个哈希函数之后,我们就可以开始引入Bloom-Filter,即布隆过滤器了,Bloom-Filter于1970年由Bloom中提出。是一种多哈希函数映射的快速查找算法。通常应用在一些需要快速判断某个元素是否属于集合,但是并不严格要求100%正确的场合。 Bloom Filter算法如下: 创建一个m位BitSet,先将所有位初始化为0,然后选择k个不同的哈希函数。第i个哈希函数对字符串str哈希的结果记为h(i,str),且h(i,str)的范围是0到m-1 。
(a) 加入字符串过程
下面是每个字符串处理的过程,首先是将字符串str“记录”到BitSet中的过程:对于字符串str,分别计算h(1,str),h(2,str)…… h(k,str)。然后将BitSet的第h(1,str)、h(2,str)…… h(k,str)位设为1。这样就将字符串str映射到 BitSet 中的k个二进制位了。
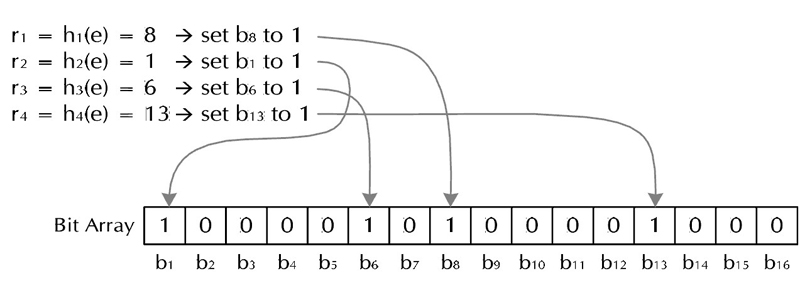
(b) 检查字符串是否存在的过程
对于字符串str,分别计算h(1,str),h(2,str)…… h(k,str)。然后检查BitSet的第h(1,str)、h(2,str)…… h(k,str)位是否为1,若其中任何一位不为1则可以判定str一定没有被记录过。若全部位都是1,则“认为”字符串str存在。
若一个字符串对应的Bit不全为1,则可以肯定该字符串一定没有被Bloom-Filter记录过。(这是显然的,因为字符串被记录过,其对应的二进制位肯定全部被设为1了)
但是若一个字符串对应的Bit全为1,实际上是不能100%的肯定该字符串被Bloom Filter记录过的。(因为有可能该字符串的所有位都刚好是被其他字符串所对应)这种将该字符串划分错的情况,称为 false positive 。
4. Bloom-Filter参数选择
哈希函数选择
哈希函数的选择对性能的影响应该是很大的,一个好的哈希函数要能近似等概率的将字符串映射到各个Bit。选择k个不同的哈希函数比较麻烦,一种简单的方法是选择一个哈希函数,然后送入k个不同的参数。
m,n,k的取值
定义: 可能把不属于这个集合的元素误认为属于这个集合(False Positive) 不会把属于这个集合的元素误认为不属于这个集合(False Negative)。 哈希函数的个数k、位数组大小m、加入的字符串数量n的关系。哈希函数个数k取10,位数组大小m设为字符串个数n的20倍时,false positive发生的概率是0.0000889 ,即10万次的判断中,会存在9次误判,对于一天1亿次的查询,误判的次数为9000次。

5. Bloom Filter的优缺点。
优点:
- 节约缓存空间(空值的映射),不再需要空值映射。
- 减少数据库或缓存的请求次数。
- 提升业务的处理效率以及业务隔离性。
缺点:
- 存在误判的概率。
- 传统的Bloom Filter不能作删除操作。
6. Bloom-Filter的应用场景
Bloom-Filter一般用于在大数据量的集合中判定某元素是否存在。
(1)适用于一些黑名单,垃圾邮件等的过滤,例如邮件服务器中的垃圾邮件过滤器。
像网易,QQ这样的公众电子邮件(email)提供商,总是需要过滤来自发送垃圾邮件的人(spamer)的垃圾邮件。
一个办法就是记录下那些发垃圾邮件的 email地址。由于那些发送者不停地在注册新的地址,全世界少说也有几十亿个发垃圾邮件的地址,将他们都存起来则需要大量的网络服务器。
采用 Bloom-Filter 方法进行存储,只需要哈希表 1/8到 1/4 的大小就能解决同样的问题。而且 BloomFilter决不会漏掉任何一个在黑名单中的可疑地址。而至于误判问题,常见的补救办法是在建立一个小的白名单,存储那些可能别误判的邮件地址。
(2)在搜索引擎领域,Bloom-Filter最常用于爬虫(Spider)的URL过滤,网络爬虫通常有一个URL列表,保存着将要下载和已经下载的网页的URL,爬虫下载了一个网页,从网页中提取到新的URL后,需要判断该URL是否已经存在于列表中。此时,Bloom-Filter算法是最好的选择。
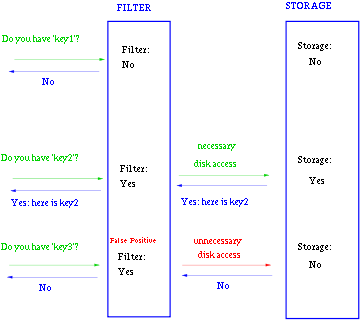
(3) 与一些 key-value 的数据库一起使用,来加快查询。 一般key-value存储系统的values存在硬盘,查询就是件费时的事。将Storage的数据都插入Filter,在Filter中查询都不存在时,那就不需要去Storage查询了。当False Position出现时,只是会导致一次多余的Storage查询。
由于Bloom-Filter所用的空间非常小,所有BF可以常驻内存。这样的话,对于大部分不存在的元素,我们只需要访问内存中的Bloom-Filter就可以判断出来了,只有一小部分,我们需要访问在硬盘上的key-value数据库。从而大大地提高了效率。如图: